25 Cleveland vs. Sacramento
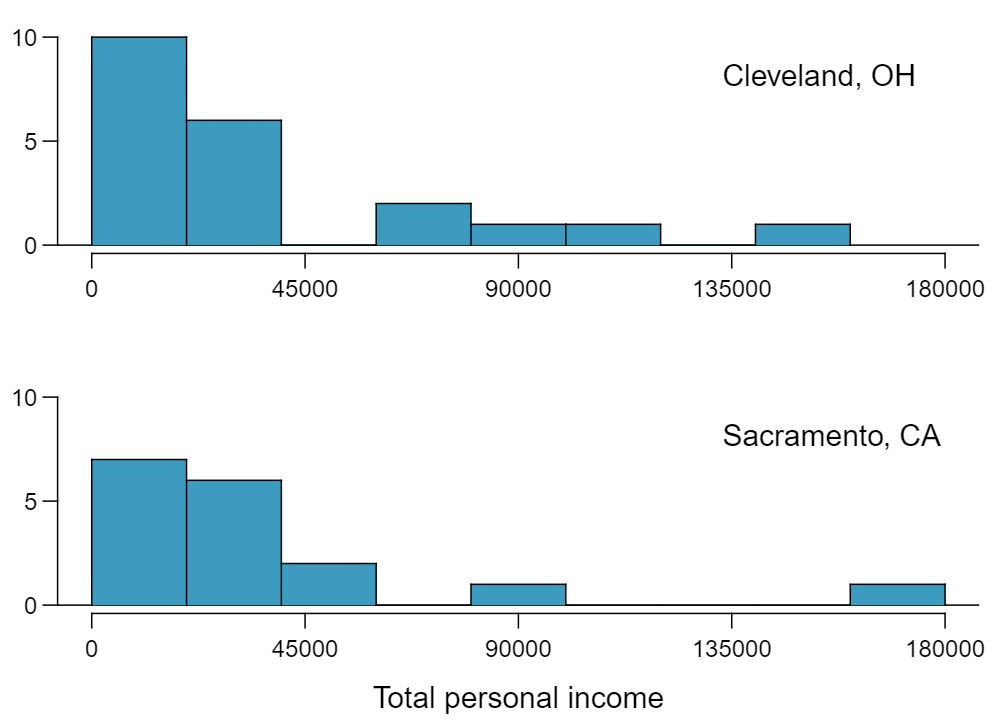
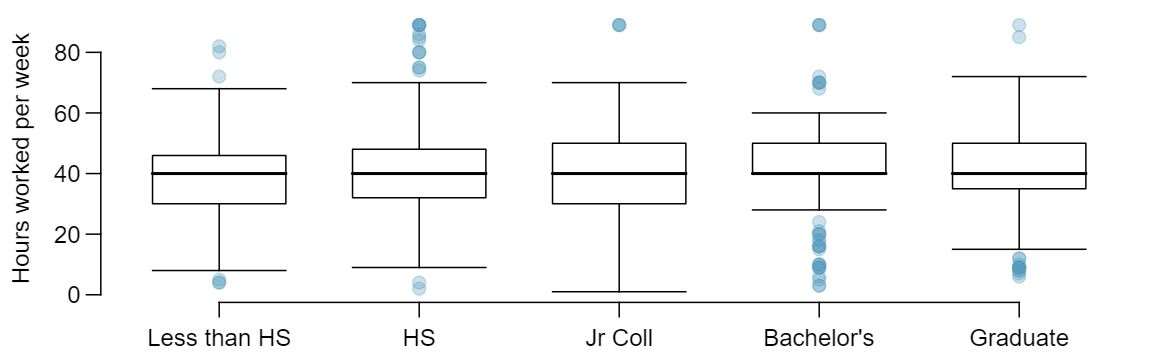
Average income varies from one region of the country to another, and it often reflects both lifestyles and regional living expenses. Suppose a new graduate is considering a job in two locations, Cleveland, OH and Sacramento, CA, and he wants to see whether the average income in one of these cities is higher than the other. He would like to conduct a hypothesis test based on two small samples from the 2000 Census, but he first must consider whether the conditions are met to implement the test. Below are histograms for each city. Should he move forward with the hypothesis test? Explain your reasoning.
|
|
|
Cleveland, OH |
|
|
| Mean |
$ 35,749 |
| SD |
$ 39,421 |
| n |
21 |
|
|
|
Sacramento, CA |
|
|
| Mean |
$ 35,500 |
| SD |
$ 41,512 |
| n |
17 |
No, he should not move forward with the test since the distributions of total personal income are very strongly skewed. When sample sizes are large, we can be a bit lenient with skew. However, such strong skew observed in this exercise would require somewhat large sample sizes, somewhat higher than 30.
26 Oscar winners
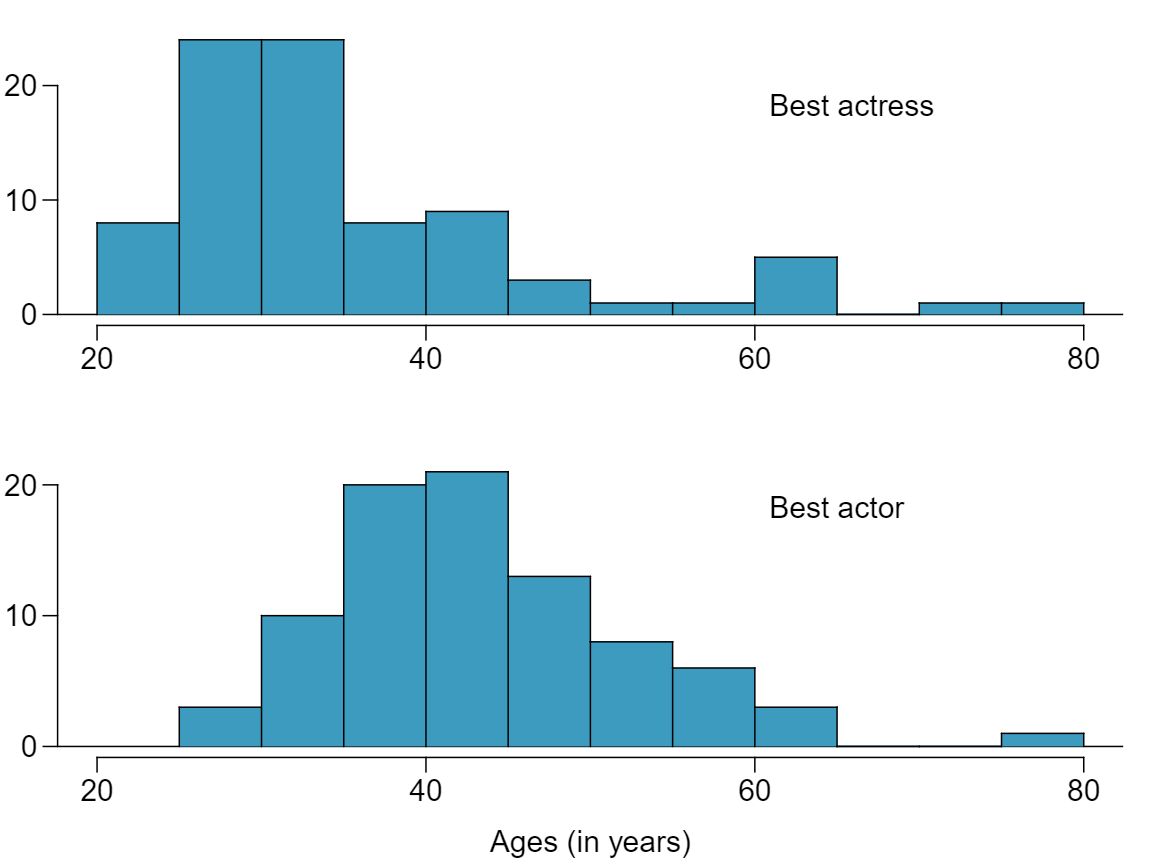
The first Oscar awards for best actor and best actress were given out in 1929. The histograms below show the age distribution for all of the best actor and best actress winners from 1929 to 2012. Summary statistics for these distributions are also provided. Is a hypothesis test appropriate for evaluating whether the difference in the average ages of best actors and actresses might be due to chance? Explain your reasoning. 4
|
|
|
Best Actress |
|
|
| Mean |
35.6 |
| SD |
11.3 |
| n |
84 |
|
|
|
Best Actor |
|
|
| Mean |
44.7 |
| SD |
8.9 |
| n |
84 |
27 Friday the 13\(^{\text{ th } }\text{,}\) Part I.
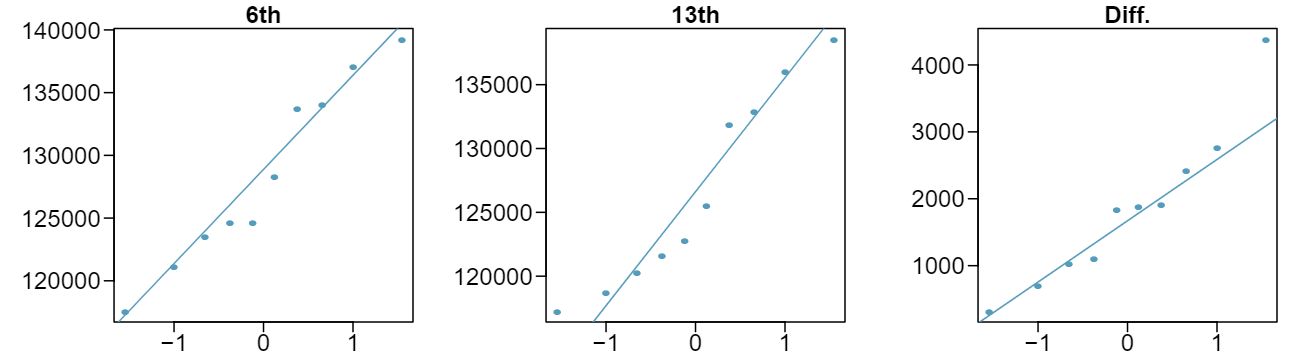
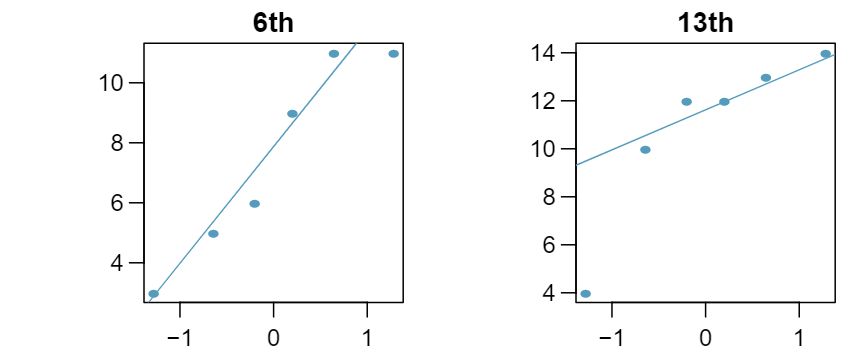
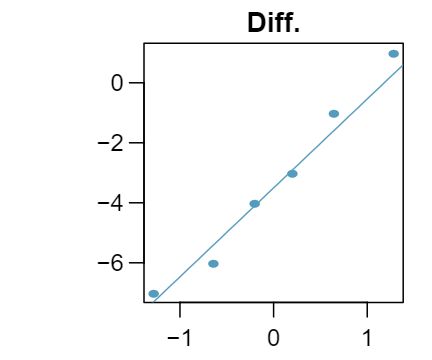
In the early 1990's, researchers in the UK collected data on traffic flow, number of shoppers, and traffic accident related emergency room admissions on Friday the 13\(^{\text{ th } }\) and the previous Friday, Friday the 6\(^{\text{ th } }\text{.}\) The histograms below show the distribution of number of cars passing by a specific intersection on Friday the 6\(^{\text{ th } }\) and Friday the 13\(^{\text{ th } }\) for many such date pairs. Also given are some sample statistics, where the difference is the number of cars on the 6th minus the number of cars on the 13th. 5
|
|
|
|
|
6\(^{\text{ th } }\) |
13\(^{\text{ th } }\) |
Diff. |
|
|
|
|
| \(\bar{x}\) |
128,385 |
126,550 |
1,835 |
| \(s\) |
7,259 |
7,664 |
1,176 |
| \(n\) |
10 |
10 |
10 |
|
|
|
|
- Are there any underlying structures in these data that should be considered in an analysis? Explain. Answer
These data are paired. For example, the Friday the 13th in say, September 1991, would probably be more similar to the Friday the 6th in September 1991 than to Friday the 6th in another month or year.
- What are the hypotheses for evaluating whether the number of people out on Friday the 6\(^{\text{ th } }\) is different than the number out on Friday the 13\(^{\text{ th } }\text{?}\) Answer
Let \(\mu_{diff} = \mu_{sixth} - \mu_{thirteenth}\text{.}\) \(H_0: \mu_{diff} = 0\text{.}\) \(H_A: \mu_{diff} \ne 0\text{.}\)
- Check conditions to carry out the hypothesis test from part (b). Answer
Independence: The months selected are not random. However, if we think these dates are roughly equivalent to a simple random sample of all such Friday 6th/13th date pairs, then independence is reasonable. To proceed, we must make this strong assumption, though we should note this assumption in any reported results. Normality: With fewer than 10 observations, we would need to use the \(t\) distribution to model the sample mean. The normal probability plot of the differences shows an approximately straight line. There isn't a clear reason why this distribution would be skewed, and since the normal quantile plot looks reasonable, we can mark this condition as reasonably satisfied.
- Calculate the test statistic and the p-value. Answer
\(T = 4.94\) for \(df=10-1=9\) \(\to\) p-value \(\lt0.01\text{.}\)
- What is the conclusion of the hypothesis test? Answer
Since p-value \(\lt\) 0.05, reject \(H_0\text{.}\) The data provide strong evidence that the average number of cars at the intersection is higher on Friday the 6\(^{\text{th}}\) than on Friday the 13\(^{\text{th}}\text{.}\) (We might believe this intersection is representative of all roads, i.e. there is higher traffic on Friday the 6\(^{\text{th}}\) relative to Friday the 13\(^{\text{th}}\text{.}\) However, we should be cautious of the required assumption for such a generalization.)
- Interpret the p-value in this context. Answer
If the average number of cars passing the intersection actually was the same on Friday the 6\(^{\text{th}}\) and \(13^{th}\text{,}\) then the probability that we would observe a test statistic so far from zero is less than 0.01.
- What type of error might have been made in the conclusion of your test? Explain. Answer
We might have made a Type 1 error, i.e. incorrectly rejected the null hypothesis.
28 Diamonds, Part I
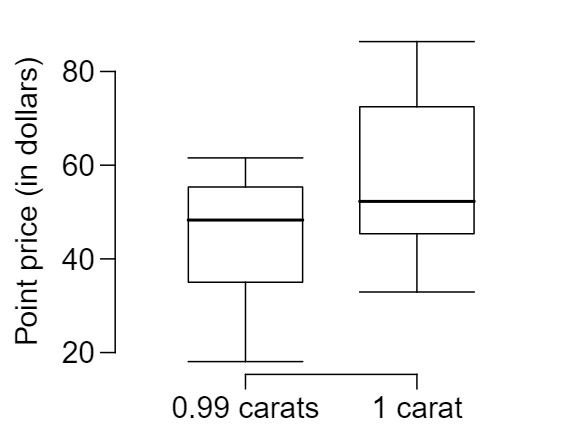
Prices of diamonds are determined by what is known as the 4 Cs: cut, clarity, color, and carat weight. The prices of diamonds go up as the carat weight increases, but the increase is not smooth. For example, the difference between the size of a 0.99 carat diamond and a 1 carat diamond is undetectable to the naked human eye, but the price of a 1 carat diamond tends to be much higher than the price of a 0.99 diamond. In this question we use two random samples of diamonds, 0.99 carats and 1 carat, each sample of size 23, and compare the average prices of the diamonds. In order to be able to compare equivalent units, we first divide the price for each diamond by 100 times its weight in carats. That is, for a 0.99 carat diamond, we divide the price by 99. For a 1 carat diamond, we divide the price by 100. The distributions and some sample statistics are shown below. 6
|
|
|
|
0.99 carats |
1 carat |
|
|
|
| Mean |
$ 44.51 |
$ 56.81 |
| SD |
$ 13.32 |
$ 16.13 |
| n |
23 |
23 |
|
|
|
29 Friday the 13\(^{\text{ th } }\text{,}\) Part II.
The Friday the \(13^{th}\) study reported in Exercise 7.5.27 also provides data on traffic accident related emergency room admissions. The distributions of these counts from Friday the 6\(^{\text{ th } }\) and Friday the 13\(^{\text{ th } }\) are shown below for six such paired dates along with summary statistics. You may assume that conditions for inference are met.
|
|
|
|
|
6\(^{\text{ th } }\) |
13\(^{\text{ th } }\) |
diff |
|
|
|
|
| Mean |
7.5 |
10.83 |
-3.33 |
| SD |
3.33 |
3.6 |
3.01 |
| n |
6 |
6 |
6 |
|
|
|
|
- Conduct a hypothesis test to evaluate if there is a difference between the average numbers of traffic accident related emergency room admissions between Friday the 6\(^{\text{ th } }\) and Friday the 13\(^{\text{ th } }\text{.}\) Answer
\(H_0: \mu_{diff} = 0\text{.}\) \(H_A: \mu_{diff} \ne 0\text{.}\) \(T=-2.71\text{.}\) \(df=5\text{.}\) \(0.02\lt\) p-value \(\lt0.05\text{.}\) Since p-value \(\lt\) 0.05, reject \(H_0\text{.}\) The data provide strong evidence that the average number of traffic accident related emergency room admissions are different between Friday the 6\(^{\text{th}}\) and Friday the 13\(^{\text{th}}\text{.}\) Furthermore, the data indicate that the direction of that difference is that accidents are lower on Friday the \(6^{th}\) relative to Friday the 13\(^{\text{th}}\text{.}\)
- Calculate a 95% confidence interval for the difference between the average numbers of traffic accident related emergency room admissions between Friday the 6\(^{\text{ th } }\) and Friday the 13\(^{\text{ th } }\text{.}\) Answer
- The conclusion of the original study states, “Friday 13th is unlucky for some. The risk of hospital admission as a result of a transport accident may be increased by as much as 52%. Staying at home is recommended.” Do you agree with this statement? Explain your reasoning. Answer
This is an observational study, not an experiment, so we cannot so easily infer a causal intervention implied by this statement. It is true that there is a difference. However, for example, this does not mean that a responsible adult going out on Friday the \(13^{th}\) has a higher chance of harm than on any other night.
30 Diamonds, Part II
In Exercise 7.5.28, we discussed diamond prices (standardized by weight) for diamonds with weights 0.99 carats and 1 carat. See the table for summary statistics, and then construct a 95% confidence interval for the average difference between the standardized prices of 0.99 and 1 carat diamonds. You may assume the conditions for inference are met.
|
|
|
|
0.99 carats |
1 carat |
|
|
|
| Mean |
$ 44.51 |
$ 56.81 |
| SD |
$ 13.32 |
$ 16.13 |
| n |
23 |
23 |
|
|
|
31 Chicken diet and weight, Part I
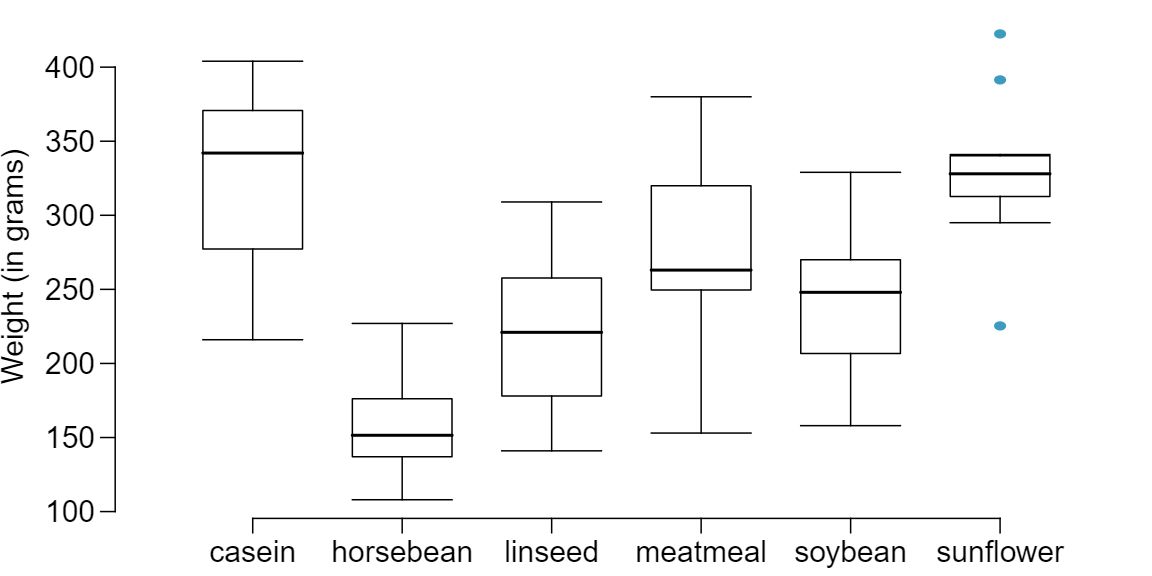
Chicken farming is a multi-billion dollar industry, and any methods that increase the growth rate of young chicks can reduce consumer costs while increasing company profits, possibly by millions of dollars. An experiment was conducted to measure and compare the effectiveness of various feed supplements on the growth rate of chickens. Newly hatched chicks were randomly allocated into six groups, and each group was given a different feed supplement. Below are some summary statistics from this data set along with box plots showing the distribution of weights by feed type. 7
|
|
|
|
|
Mean |
SD |
n |
|
|
|
|
| casein |
323.58 |
64.43 |
12 |
| horsebean |
160.20 |
38.63 |
10 |
| linseed |
218.75 |
52.24 |
12 |
| meatmeal |
276.91 |
64.90 |
11 |
| soybean |
246.43 |
54.13 |
14 |
| sunflower |
328.92 |
48.84 |
12 |
|
|
|
|
- Describe the distributions of weights of chickens that were fed linseed and horsebean. Answer
Chicken fed linseed weighed an average of 218.75 grams while those fed horsebean weighed an average of 160.20 grams. Both distributions are relatively symmetric with no apparent outliers. There is more variability in the weights of chicken fed linseed.
- Do these data provide strong evidence that the average weights of chickens that were fed linseed and horsebean are different? Use a 5% significance level. Answer
\(H_0: \mu_{ls} = \mu_{hb}\text{.}\) \(H_A: \mu_{ls} \ne \mu_{hb}\text{.}\) We leave the conditions to you to consider. \(T=3.02\text{,}\) \(df = min(11, 9) = 9\) \(\to\) \(0.01\lt\) p-value \(\lt0.02\text{.}\) Since p-value \(\lt\) 0.05, reject \(H_0\text{.}\) The data provide strong evidence that there is a significant difference between the average weights of chickens that were fed linseed and horsebean.
- What type of error might we have committed? Explain. Answer
Type 1, since we rejected \(H_0\text{.}\)
- Would your conclusion change if we used \(\alpha = 0.01\text{?}\) Answer
Yes, since p-value \(\gt\) 0.01, we would have failed to reject \(H_0\text{.}\)
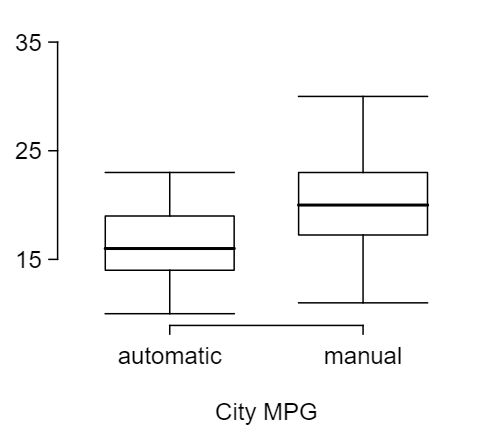
32 Fuel efficiency of manual and automatic cars, Part I
Each year the US Environmental Protection Agency (EPA) releases fuel economy data on cars manufactured in that year. Below are summary statistics on fuel efficiency (in miles/gallon) from random samples of cars with manual and automatic transmissions manufactured in 2012. Do these data provide strong evidence of a difference between the average fuel efficiency of cars with manual and automatic transmissions in terms of their average city mileage? Assume that conditions for inference are satisfied. 8
|
|
|
|
City MPG |
|
|
|
|
Automatic |
Manual |
| Mean |
16.12 |
19.85 |
| SD |
3.58 |
4.51 |
| n |
26 |
26 |
|
|
|
|
|
|
|
33 Chicken diet and weight, Part II
Casein is a common weight gain supplement for humans. Does it have an effect on chickens? Using data provided in Exercise 7.5.31, test the hypothesis that the average weight of chickens that were fed casein is different than the average weight of chickens that were fed soybean. If your hypothesis test yields a statistically significant result, discuss whether or not the higher average weight of chickens can be attributed to the casein diet. Assume that conditions for inference are satisfied.
Answer\(H_0: \mu_C = \mu_S\text{.}\) \(H_A: \mu_C \ne \mu_S\text{.}\) \(T = 3.27\text{,}\) \(df=11\) \(\to\) p-value \(\lt0.01\text{.}\) Since p-value \(\lt 0.05\text{,}\) reject \(H_0\text{.}\) The data provide strong evidence that the average weight of chickens that were fed casein is different than the average weight of chickens that were fed soybean (with weights from casein being higher). Since this is a randomized experiment, the observed difference can be attributed to the diet.
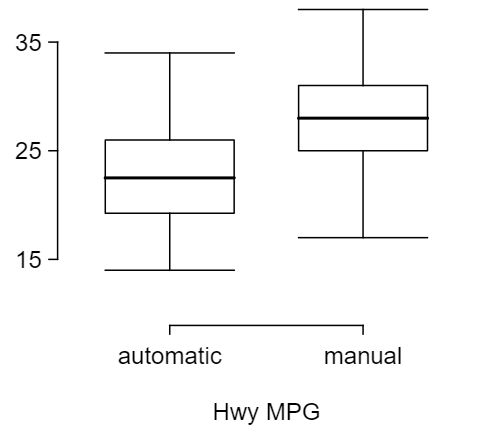
34 Fuel efficiency of manual and automatic cars, Part II
The table provides summary statistics on highway fuel economy of cars manufactured in 2012 (from Exercise 7.5.32). Use these statistics to calculate a 98% confidence interval for the difference between average highway mileage of manual and automatic cars, and interpret this interval in the context of the data. 9
|
|
|
|
Hwy MPG |
|
|
|
|
Automatic |
Manual |
| Mean |
22.92 |
27.88 |
| SD |
5.29 |
5.01 |
| n |
26 |
26 |
|
|
|
|
|
|
|
35 Gaming and distracted eating, Part I
A group of researchers are interested in the possible effects of distracting stimuli during eating, such as an increase or decrease in the amount of food consumption. To test this hypothesis, they monitored food intake for a group of 44 patients who were randomized into two equal groups. The treatment group ate lunch while playing solitaire, and the control group ate lunch without any added distractions. Patients in the treatment group ate 52.1 grams of biscuits, with a standard deviation of 45.1 grams, and patients in the control group ate 27.1 grams of biscuits, with a standard deviation of 26.4 grams. Do these data provide convincing evidence that the average food intake (measured in amount of biscuits consumed) is different for the patients in the treatment group? Assume that conditions for inference are satisfied. 10
Answer\(H_0: \mu_{T} = \mu_{C}\text{.}\) \(H_A: \mu_{T} \ne \mu_{C}\text{.}\) \(T=2.24\text{,}\) \(df=21\) \(\to\) \(0.02\lt\) p-value \(\lt0.05\text{.}\) Since p-value \(\lt\) 0.05, reject \(H_0\text{.}\) The data provide strong evidence that the average food consumption by the patients in the treatment and control groups are different. Furthermore, the data indicate patients in the distracted eating (treatment) group consume more food than patients in the control group.
36 Gaming and distracted eating, Part II
The researchers from Exercise 7.5.35 also investigated the effects of being distracted by a game on how much people eat. The 22 patients in the treatment group who ate their lunch while playing solitaire were asked to do a serial-order recall of the food lunch items they ate. The average number of items recalled by the patients in this group was 4.9, with a standard deviation of 1.8. The average number of items recalled by the patients in the control group (no distraction) was 6.1, with a standard deviation of 1.8. Do these data provide strong evidence that the average number of food items recalled by the patients in the treatment and control groups are different?
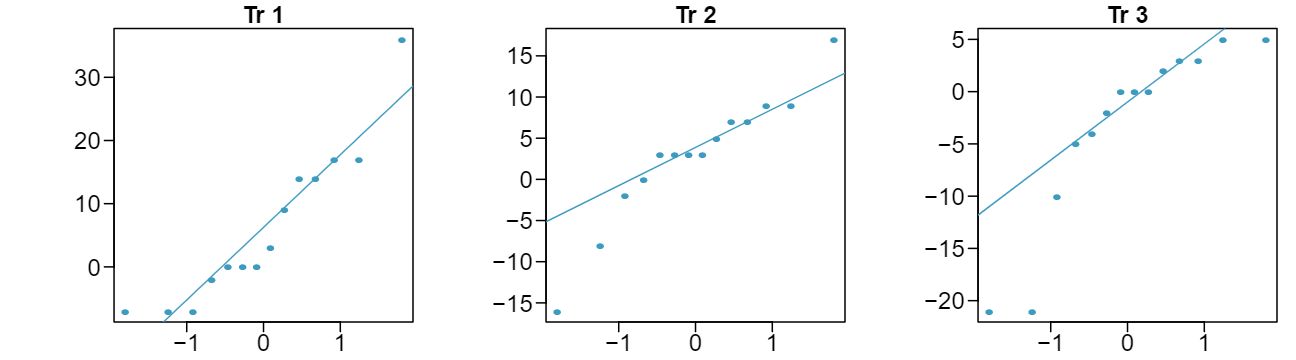
37 Prison isolation experiment, Part I
Subjects from Central Prison in Raleigh, NC, volunteered for an experiment involving an “isolation” experience. The goal of the experiment was to find a treatment that reduces subjects' psychopathic deviant \(T\)-scores. This score measures a person's need for control or their rebellion against control, and it is part of a commonly used mental health test called the Minnesota Multiphasic Personality Inventory (MMPI) test. The experiment had three treatment groups:
- Four hours of sensory restriction plus a 15 minute “therapeutic” tape advising that professional help is available.
- Four hours of sensory restriction plus a 15 minute “emotionally neutral” tape on training hunting dogs.
- Four hours of sensory restriction but no taped message.
Forty-two subjects were randomly assigned to these treatment groups, and an MMPI test was administered before and after the treatment. Distributions of the differences between pre and post treatment scores (pre - post) are shown below, along with some sample statistics. Use this information to independently test the effectiveness of each treatment. Make sure to clearly state your hypotheses, check conditions, and interpret results in the context of the data. 11
|
|
|
|
|
|
Tr 1 |
Tr 2 |
Tr 3 |
|
|
|
|
|
| Mean |
6.21 |
2.86 |
-3.21 |
| SD |
12.3 |
7.94 |
8.57 |
| n |
14 |
14 |
14 |
|
|
|
|
|
Let \(\mu_{diff} = \mu_{pre} - \mu_{post}\text{.}\) \(H_0: \mu_{diff} = 0\text{:}\) Treatment has no effect. \(H_A: \mu_{diff} \gt 0\text{:}\) Treatment is effective in reducing Pd T scores, the average pre-treatment score is higher than the average post-treatment score. Note that the reported values are pre minus post, so we are looking for a positive difference, which would correspond to a reduction in the psychopathic deviant T score. Conditions are checked as follows. Independence: The subjects are randomly assigned to treatments, so the patients in each group are independent. All three sample sizes are smaller than 30, so we use \(t\)-tests. Distributions of differences are somewhat skewed. The sample sizes are small, so we cannot reliably relax this assumption. (We will proceed, but we would not report the results of this specific analysis, at least for treatment group 1.) For all three groups: \(df=13\text{.}\) \(T_1= 1.89\) (\(0.025\lt\) p-value \(\lt0.05\)), \(T_2=1.35\) (p-value = 0.10), \(T_3 = -1.40\) (p-value \(\gt0.10\)). The only significant test reduction is found in Treatment 1, however, we had earlier noted that this result might not be reliable due to the skew in the distribution. Note that the calculation of the p-value for Treatment 3 was unnecessary: the sample mean indicated a increase in Pd T scores under this treatment (as opposed to a decrease, which was the result of interest). That is, we could tell without formally completing the hypothesis test that the p-value would be large for this treatment group.
38 True / False: comparing means
Determine if the following statements are true or false, and explain your reasoning for statements you identify as false.
When comparing means of two samples where \(n_1 = 20\) and \(n_2 = 40\text{,}\) we can use the normal model for the difference in means since \(n_2 \ge 30\text{.}\)
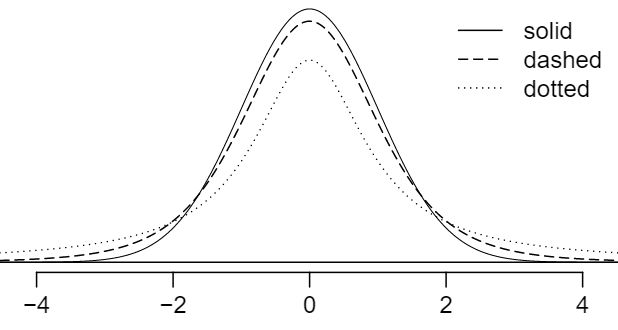
As the degrees of freedom increases, the \(t\)-distribution approaches normality.
We use a pooled standard error for calculating the standard error of the difference between means when sample sizes of groups are equal to each other.