
Section 2.4 Case study: malaria vaccine (special topic)
¶How large does an observed difference need to be for it to provide convincing evidence that something real is going on, something beyond random variation? Answering this question requires the tools that we will encounter in the later chapters on probability and inference. However, this is such an interesting and important question, and we'll also address it here using simulation. This section can be covered now or in tandem with Chapter 5: Foundations for Inference.
Subsection 2.4.1 Learning objectives
Recognize that an observed difference in sample statistics may be due to random chance and that we use hypothesis testing to determine if this is difference statistically significant (i.e. too large to be attributed to random chance).
Set up competing hypotheses and use the results of a simulation to evaluate the degree of support the data provide against the null hypothesis and for the alternative hypothesis.
Subsection 2.4.2 Variability within data
¶Example 2.4.1.
Suppose your professor splits the students in class into two groups: students on the left and students on the right. If \(\hat{p}_{L}\) and \(\hat{p}_{R}\) represent the proportion of students who own an Apple product on the left and right, respectively, would you be surprised if \(\hat{p}_{L}\) did not exactly equal \(\hat{p}_{R}\text{?}\)
While the proportions would probably be close to each other, it would be unusual for them to be exactly the same. We would probably observe a small difference due to chance.
Checkpoint 2.4.2.
If we don't think the side of the room a person sits on in class is related to whether the person owns an Apple product, what assumption are we making about the relationship between these two variables? 1
We consider a study on a new malaria vaccine called PfSPZ. In this study, volunteer patients were randomized into one of two experiment groups: 14 patients received an experimental vaccine and 6 patients received a placebo vaccine. Nineteen weeks later, all 20 patients were exposed to a drug-sensitive malaria virus strain; the motivation of using a drug-sensitive strain of virus here is for ethical considerations, allowing any infections to be treated effectively. The results are summarized in Table 2.4.3, where 9 of the 14 treatment patients remained free of signs of infection while all of the 6 patients in the control group patients showed some baseline signs of infection.
outcome |
|||||
| infection | no infection | Total | |||
treatment |
vaccine | 5 | 9 | 14 | |
| placebo | 6 | 0 | 6 | ||
| Total | 11 | 9 | 20 | ||
Checkpoint 2.4.4.
Is this an observational study or an experiment? What implications does the study type have on what can be inferred from the results? 2
In this study, a smaller proportion of patients who received the vaccine showed signs of an infection (35.7% versus 100%). However, the sample is very small, and it is unclear whether the difference provides convincing evidence that the vaccine is effective.
Example 2.4.5.
Data scientists are sometimes called upon to evaluate the strength of evidence. When looking at the rates of infection for patients in the two groups in this study, what comes to mind as we try to determine whether the data show convincing evidence of a real difference?
The observed infection rates (35.7% for the treatment group versus 100% for the control group) suggest the vaccine may be effective. However, we cannot be sure if the observed difference represents the vaccine's efficacy or is just from random chance. Generally there is a little bit of fluctuation in sample data, and we wouldn't expect the sample proportions to be exactly equal, even if the truth was that the infection rates were independent of getting the vaccine. Additionally, with such small samples, perhaps it's common to observe such large differences when we randomly split a group due to chance alone!
Solution 2.4.5.1 is a reminder that the observed outcomes in the data sample may not perfectly reflect the true relationships between variables since there is random noise. While the observed difference in rates of infection is large, the sample size for the study is small, making it unclear if this observed difference represents efficacy of the vaccine or whether it is simply due to chance. We label these two competing claims, \(H_0\) and \(H_A\text{,}\) which are spoken as “H-nought” and “H-A”:
\(H_0\text{:}\) Independence model. The variables
treatmentandoutcomeare independent. They have no relationship, and the observed difference between the proportion of patients who developed an infection in the two groups, 64.3%, was due to chance.\(H_A\text{:}\) Alternative model. The variables are not independent. The difference in infection rates of 64.3% was not due to chance, and the vaccine affected the rate of infection.
What would it mean if the independence model, which says the vaccine had no influence on the rate of infection, is true? It would mean 11 patients were going to develop an infection no matter which group they were randomized into, and 9 patients would not develop an infection no matter which group they were randomized into. That is, if the vaccine did not affect the rate of infection, the difference in the infection rates was due to chance alone in how the patients were randomized.
Now consider the alternative model: infection rates were influenced by whether a patient received the vaccine or not. If this was true, and especially if this influence was substantial, we would expect to see some difference in the infection rates of patients in the groups.
We choose between these two competing claims by assessing if the data conflict so much with \(H_0\) that the independence model cannot be deemed reasonable. If this is the case, and the data support \(H_A\text{,}\) then we will reject the notion of independence and conclude the vaccine affected the rate of infection.
Subsection 2.4.3 Simulating the study
¶We're going to implement simulations, where we will pretend we know that the malaria vaccine being tested does not work. Ultimately, we want to understand if the large difference we observed is common in these simulations. If it is common, then maybe the difference we observed was purely due to chance. If it is very uncommon, then the possibility that the vaccine was helpful seems more plausible.
Table 2.4.3 shows that 11 patients developed infections and 9 did not. For our simulation, we will suppose the infections were independent of the vaccine and we were able to rewind back to when the researchers randomized the patients in the study. If we happened to randomize the patients differently, we may get a different result in this hypothetical world where the vaccine doesn't influence the infection. Let's complete another randomization using a simulation.
In this simulation, we take 20 notecards to represent the 20 patients, where we write down “infection” on 11 cards and “no infection” on 9 cards. In this hypothetical world, we believe each patient that got an infection was going to get it regardless of which group they were in, so let's see what happens if we randomly assign the patients to the treatment and control groups again. We thoroughly shuffle the notecards and deal 14 into a vaccine pile and 6 into a placebo pile. Finally, we tabulate the results, which are shown in Table 2.4.6.
outcome |
|||||
| infection | no infection | Total | |||
| treatment (simulated) |
vaccine | 7 | 7 | 14 | |
| placebo | 4 | 2 | 6 | ||
| Total | 11 | 9 | 20 | ||
Checkpoint 2.4.7.
What is the difference in infection rates between the two simulated groups in Table 2.4.6? How does this compare to the observed 64.3% difference in the actual data? 3
Subsection 2.4.4 Checking for independence
We computed one possible difference under the independence model in Checkpoint 2.4.7, which represents one difference due to chance. While in this first simulation, we physically dealt out notecards to represent the patients, it is more efficient to perform this simulation using a computer. Repeating the simulation on a computer, we get another difference due to chance:
And another:
And so on until we repeat the simulation enough times that we have a good idea of what represents the distribution of differences from chance alone. Figure 2.4.8 shows a stacked plot of the differences found from 100 simulations, where each dot represents a simulated difference between the infection rates (control rate minus treatment rate).
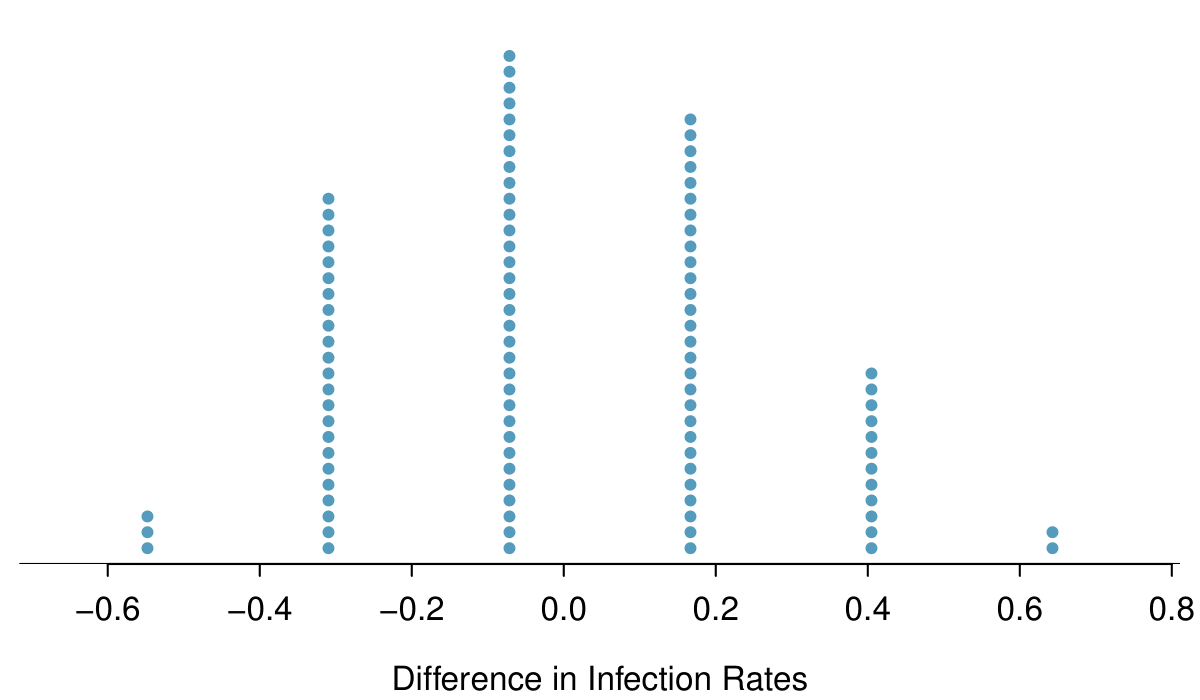
Note that the distribution of these simulated differences is centered around 0. We simulated these differences assuming that the independence model was true, and under this condition, we expect the difference to be near zero with some random fluctuation, where near is pretty generous in this case since the sample sizes are so small in this study.
Example 2.4.9.
Given the results of the simulation shown in Figure 2.4.8, about how often would you expect to observe a result as large as 64.3% if \(H_0\) were true?
Because a result this large happened 2 times out the 100 simulations, we would expect such a large value only 2% of the time if \(H_0\) were true.
There are two possible interpretations of the results of the study:
\(H_0\text{:}\) Independence model. The vaccine has no effect on infection rate, and we just happened to observe a rare event.
\(H_A\text{:}\) Alternative model. The vaccine has an effect on infection rate, and the difference we observed was actually due to the vaccine being effective at combatting malaria, which explains the large difference of 64.3%.
Based on the simulations, we have two options. (1) We conclude that the study results do not provide strong enough evidence against the independence model, meaning we do not conclude that the vaccine had an effect in this clinical setting. (2) We conclude the evidence is sufficiently strong to reject \(H_0\text{,}\) and we assert that the vaccine was useful.
Is 2% small enough to make us reject the independence model? That depends on how much evidence we require. The smaller that probability is, the more evidence it provides against \(H_0\text{.}\) Later, we will see that researchers often use a cutoff of 5%, though it can depend upon the situation. Using the 5% cutoff, we would reject the independence model in favor of the alternative. That is, we are concluding the data provide strong evidence that the vaccine provides some protection against malaria in this clinical setting.
When there is strong enough evidence that the result points to a real difference and is not simply due to random variation, we call the result statistically significant.
One field of statistics, statistical inference, is built on evaluating whether such differences are due to chance. In statistical inference, data scientists evaluate which model is most reasonable given the data. Errors do occur, just like rare events, and we might choose the wrong model. While we do not always choose correctly, statistical inference gives us tools to control and evaluate how often these errors occur. In Chapter 5, we give a formal introduction to the problem of model selection. We spend the next two chapters building a foundation of probability and theory necessary to make that discussion rigorous.
Exercises 2.4.5 Exercises
1. Side effects of Avandia.
Rosiglitazone is the active ingredient in the controversial type 2 diabetes medicine Avandia and has been linked to an increased risk of serious cardiovascular problems such as stroke, heart failure, and death. A common alternative treatment is pioglitazone, the active ingredient in a diabetes medicine called Actos. In a nationwide retrospective observational study of 227,571 Medicare beneficiaries aged 65 years or older, it was found that 2,593 of the 67,593 patients using rosiglitazone and 5,386 of the 159,978 using pioglitazone had serious cardiovascular problems. These data are summarized in the contingency table below. 4
| Cardiovascular problems | ||||
| Yes | No | Total | ||
| Treatment | Rosiglitazone | 2,593 | 65,000 | 67,593 |
| Pioglitazone | 5,386 | 154,592 | 159,978 | |
| Total | 7,979 | 219,592 | 227,571 | |
-
Determine if each of the following statements is true or false. If false, explain why. Be careful: The reasoning may be wrong even if the statement's conclusion is correct. In such cases, the statement should be considered false.
Since more patients on pioglitazone had cardiovascular problems (5,386 vs. 2,593), we can conclude that the rate of cardiovascular problems for those on a pioglitazone treatment is higher.
The data suggest that diabetic patients who are taking rosiglitazone are more likely to have cardiovascular problems since the rate of incidence was \((2,593 / 67,593 = 0.038)\) 3.8% for patients on this treatment, while it was only \((5,386 / 159,978 = 0.034)\) 3.4% for patients on pioglitazone.
The fact that the rate of incidence is higher for the rosiglitazone group proves that rosiglitazone causes serious cardiovascular problems.
Based on the information provided so far, we cannot tell if the difference between the rates of incidences is due to a relationship between the two variables or due to chance.
What proportion of all patients had cardiovascular problems?
If the type of treatment and having cardiovascular problems were independent, about how many patients in the rosiglitazone group would we expect to have had cardiovascular problems?
-
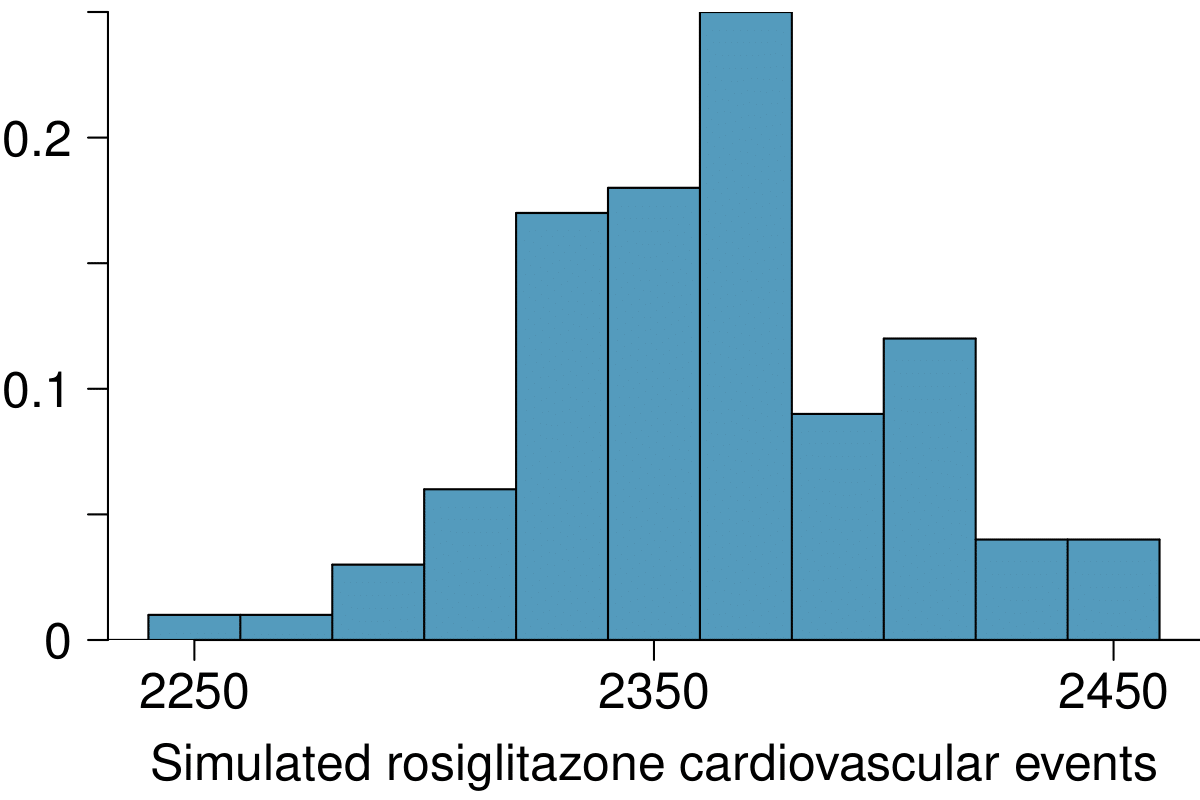
We can investigate the relationship between outcome and treatment in this study using a randomization technique. While in reality we would carry out the simulations required for randomization using statistical software, suppose we actually simulate using index cards. In order to simulate from the independence model, which states that the outcomes were independent of the treatment, we write whether or not each patient had a cardiovascular problem on cards, shuffled all the cards together, then deal them into two groups of size 67,593 and 159,978. We repeat this simulation 1,000 times and each time record the number of people in the rosiglitazone group who had cardiovascular problems. Use the relative frequency histogram of these counts to answer (i)-(iii).
What are the claims being tested?
Compared to the number calculated in part (b), which would provide more support for the alternative hypothesis, more or fewer patients with cardiovascular problems in the rosiglitazone group?
What do the simulation results suggest about the relationship between taking rosiglitazone and having cardiovascular problems in diabetic patients?
(a) (i) False. Instead of comparing counts, we should compare percentages of people in each group who suffered cardiovascular problems. (ii) True. (iii) False. Association does not imply causation. We cannot infer a causal relationship based on an observational study. The difference from part (ii) is subtle. (iv) True.
(b) Proportion of all patients who had cardiovascular problems: \(\frac{7,979}{227,571} \approx 0.035\)
(c) The expected number of heart attacks in the rosiglitazone group, if having cardiovascular problems and treatment were independent, can be calculated as the number of patients in that group multiplied by the overall cardiovascular problem rate inthe study: \(67,593 \times \frac{7,979}{227,571}=2370\text{.}\)
(d) (i) \(H_{0}\text{:}\) The treatment and cardiovascular problems are independent. They have no relationship, and the difference in incidence rates between the rosiglitazone and pioglitazone groups is due to chance. \(H_{A}\text{:}\) The treatment and cardiovascular problems are not independent. The difference in the incidence rates between the rosiglitazone and pioglitazone groups is not due to chance and rosiglitazone is associated with an increased risk of serious cardiovascular problems. (ii) A higher number of patients with cardiovascular problems than expected under the assumption of independence would provide support for the alternative hypothesis as this would suggest that rosiglitazone increases the risk of such problems. (iii) In the actual study, we observed 2,593 cardiovascular events in the rosiglitazone group. In the 1,000 simulations under the independence model, we observed somewhat less than 2,593 in every single simulation, which suggests that the actual results did not come from the independence model. That is, the variables do not appear to be independent, and we reject the independence model in favor of the alternative. The study's results provide convincing evidence that rosiglitazone is associated with an increased risk of cardiovascular problems.
2. Heart transplants.
The Stanford University Heart Transplant Study was conducted to determine whether an experimental heart transplant program increased lifespan. Each patient entering the program was designated an official heart transplant candidate, meaning that he was gravely ill and would most likely benefit from a new heart. Some patients got a transplant and some did not. The variable transplant indicates which group the patients were in; patients in the treatment group got a transplant and those in the control group did not. Of the 34 patients in the control group, 30 died. Of the 69 people in the treatment group, 45 died. Another variable called survived was used to indicate whether or not the patient was alive at the end of the study. 5
Based on the mosaic plot, is survival independent of whether or not the patient got a transplant? Explain your reasoning.
What do the box plots below suggest about the efficacy (effectiveness) of the heart transplant treatment.
What proportion of patients in the treatment group and what proportion of patients in the control group died?
-
One approach for investigating whether or not the treatment is effective is to use a randomization technique.
What are the claims being tested?
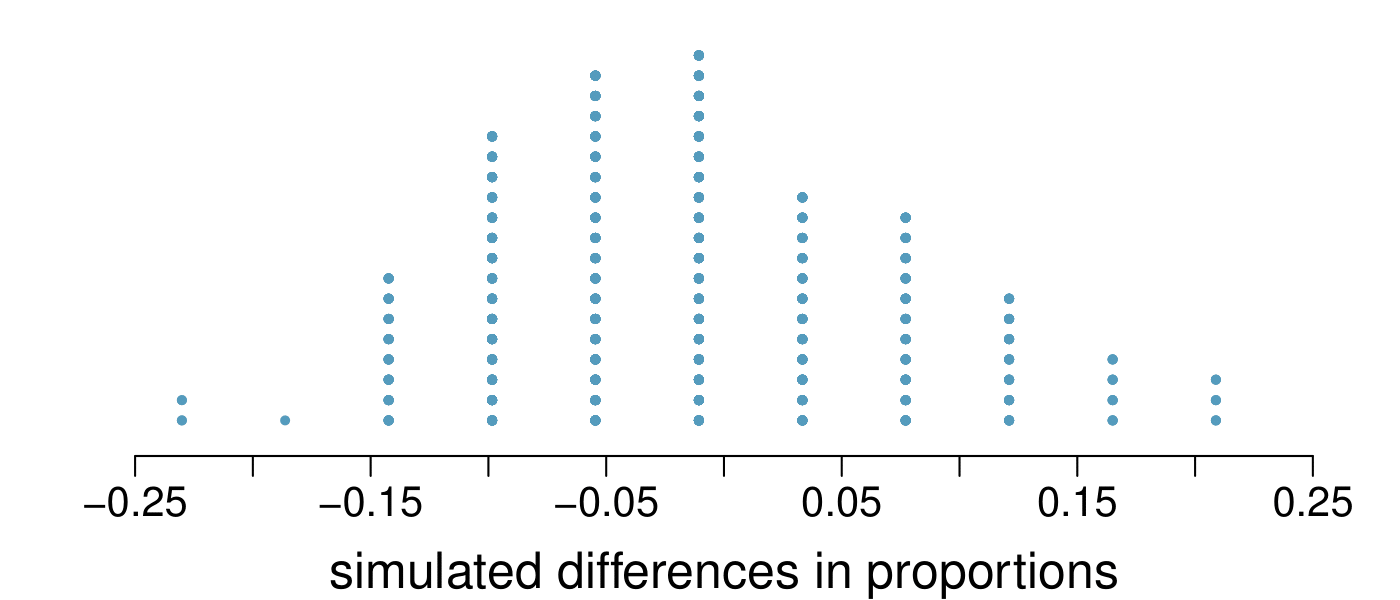
The paragraph below describes the set up for such approach, if we were to do it without using statistical software. Fill in the blanks with a number or phrase, whichever is appropriate. We write alive on ________ cards representing patients who were alive at the end of the study, and dead on ___________ cards representing patients who were not. Then, we shuffle these cards and split them into two groups: one group of size ___________ representing treatment, and another group of size ___________ representing control. We calculate the difference between the proportion of dead cards in the treatment and control groups (treatment - control) and record this value. We repeat this 100 times to build a distribution centered at ___________. Lastly, we calculate the fraction of simulations where the simulated differences in proportions are ___________. If this fraction is low, we conclude that it is unlikely to have observed such an outcome by chance and that the null hypothesis should be rejected in favor of the alternative.
-
What do the simulation results shown below suggest about the effectiveness of the transplant program?
Subsection 2.4.6 Chapter Highlights
A raw data matrix/table may have thousands of rows. The data need to be summarized in order to makes sense of all the information. In this chapter, we looked at ways to summarize data graphically, numerically, and verbally.
Categorical data
A single categorical variable is summarized with counts or proportions in a one-way table. A bar chart is used to show the frequency or relative frequency of the categories that the variable takes on.
Two categorical variables can be summarized in a two-way table and with a side-by-side bar chart or a segmented bar chart.
Numerical data
When looking at a single numerical variable, we try to understand the distribution of the variable. The distribution of a variable can be represented with a frequency table and with a graph, such as a stem-and-leaf plot or dot plot for small data sets, or a histogram for larger data sets. If only a summary is desired, a box plot may be used.
The distribution of a variable can be described and summarized with center (mean or median), spread (SD or IQR), and shape (right skewed, left skewed, approximately symmetric).
Z-scores and percentiles are useful for identifying a data point's relative position within a data set.
Outliers are values that appear extreme relative to the rest of the data. Investigating outliers can provide insight into properties of the data or may reveal data collection/entry errors.
When comparing the distribution of two variables, use two dot plots, two histograms, a back-to-back stem-and-leaf, or parallel box plots.
To look at the association between two numerical variables, use a scatterplot.
Graphs and numbers can summarize data, but they alone are insufficient. It is the role of the researcher or data scientist to ask questions, to use these tools to identify patterns and departure from patterns, and to make sense of this in the context of the data. Strong writing skills are critical for being able to communicate the results to a wider audience.