
Section 7.4 Chapter exercises
¶Exercises 7.4.1 Exercises
1. Gaming and distracted eating, Part I.
A group of researchers are interested in the possible effects of distracting stimuli during eating, such as an increase or decrease in the amount of food consumption. To test this hypothesis, they monitored food intake for a group of 44 patients who were randomized into two equal groups. The treatment group ate lunch while playing solitaire, and the control group ate lunch without any added distractions. Patients in the treatment group ate 52.1 grams of biscuits, with a standard deviation of 45.1 grams, and patients in the control group ate 27.1 grams of biscuits, with a standard deviation of 26.4 grams. Do these data provide convincing evidence that the average food intake (measured in amount of biscuits consumed) is different for the patients in the treatment group? Assume that conditions for inference are satisfied. 1
\(H_{0} : \mu_{T} = \mu_{C}\text{.}\) \(H_{A} : \mu_{T} \ne \mu_{C}\text{.}\) \(T = 2.24\text{,}\) \(df = 21 \rightarrow \text{p-value } = 0.036\text{.}\) Since \(\text{p-value } < 0.05\text{,}\) reject \(H_{0}\text{.}\) The data provide strong evidence that the average food consumption by the patients in the treatment and control groups are different. Furthermore, the data indicate patients in the distracted eating (treatment) group consume more food than patients in the control group.
2. Gaming and distracted eating, Part II.
The researchers from Exercise 7.4.1.1 also investigated the effects of being distracted by a game on how much people eat. The 22 patients in the treatment group who ate their lunch while playing solitaire were asked to do a serial-order recall of the food lunch items they ate. The average number of items recalled by the patients in this group was 4. 9, with a standard deviation of 1.8. The average number of items recalled by the patients in the control group (no distraction) was 6.1, with a standard deviation of 1.8. Do these data provide strong evidence that the average number of food items recalled by the patients in the treatment and control groups are different?
3. Sample size and pairing.
Determine if the following statement is true or false, and if false, explain your reasoning: If comparing means of two groups with equal sample sizes, always use a paired test.
False. While it is true that paired analysis requires equal sample sizes, only having the equal sample sizes isn't, on its own, sufficient for doing a paired test. Paired tests require that there be a special correspondence between each pair of observations in the two groups.
4. College credits.
A college counselor is interested in estimating how many credits a student typically enrolls in each semester. The counselor decides to randomly sample 100 students by using the registrar's database of students. The histogram below shows the distribution of the number of credits taken by these students. Sample statistics for this distribution are also provided.
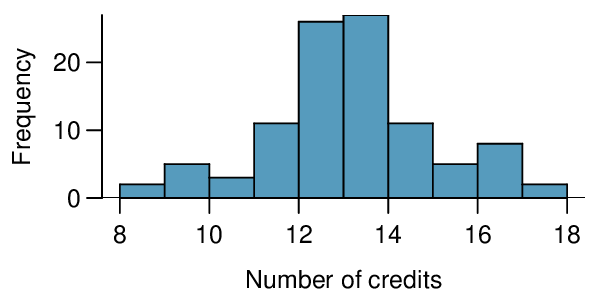
| Min | 8 |
| Q1 | 13 |
| Median | 14 |
| Mean | 13.65 |
| SD | 1.91 |
| Q3 | 15 |
| Max | 18 |
What is the point estimate for the average number of credits taken per semester by students at this college? What about the median?
What is the point estimate for the standard deviation of the number of credits taken per semester by students at this college? What about the IQR?
Is a load of 16 credits unusually high for this college? What about 18 credits? Explain your reasoning.
The college counselor takes another random sample of 100 students and this time finds a sample mean of 14.02 units. Should she be surprised that this sample statistic is slightly different than the one from the original sample? Explain your reasoning.
The sample means given above are point estimates for the mean number of credits taken by all students at that college. What measures do we use to quantify the variability of this estimate? Compute this quantity using the data from the original sample.
5. Hen eggs.
The distribution of the number of eggs laid by a certain species of hen during their breeding period has a mean of 35 eggs with a standard deviation of 18.2. Suppose a group of researchers randomly samples 45 hens of this species, counts the number of eggs laid during their breeding period, and records the sample mean. They repeat this 1,000 times, and build a distribution of sample means.
What is this distribution called?
Would you expect the shape of this distribution to be symmetric, right skewed, or left skewed? Explain your reasoning.
Calculate the variability of this distribution and state the appropriate term used to refer to this value.
Suppose the researchers' budget is reduced and they are only able to collect random samples of 10 hens. The sample mean of the number of eggs is recorded, and we repeat this 1,000 times, and build a new distribution of sample means. How will the variability of this new distribution compare to the variability of the original distribution?
(a) We are building a distribution of sample statistics, in this case the sample mean. Such a distribution is called a sampling distribution.
(b) Because we are dealing with the distribution of sample means, we need to check to see if the Central Limit Theorem applies. Our sample size is greater than 30, and we are told that random sampling is employed. With these conditions met, we expect that the distribution of the sample mean will be nearly normal and therefore symmetric.
(c) Because we are dealing with a sampling distribution, we measure its variability with the standard error. \(SE = 18.2/ \sqrt{45} = 2.713\)
(d) The sample means will be more variable with the smaller sample size.
6. Forest management.
Forest rangers wanted to better understand the rate of growth for younger trees in the park. They took measurements of a random sample of 50 young trees in 2009 and again measured those same trees in 2019. The data below summarize their measurements, where the heights are in feet:
| 2009 | 2010 | Differences | |
| \(\bar{x}\) | 12.0 | 24.5 | 12.5 |
| \(s\) | 3.5 | 9.5 | 7.2 |
| \(n\) | 50 | 50 | 50 |
Construct a 99% confidence interval for the average growth of (what had been) younger trees in the park over 2009-2019.
7. Exclusive relationships.
A survey conducted on a reasonably random sample of 203 undergraduates asked, among many other questions, about the number of exclusive relationships these students have been in. The histogram below shows the distribution of the data from this sample. The sample average is 3.2 with a standard deviation of 1.97.
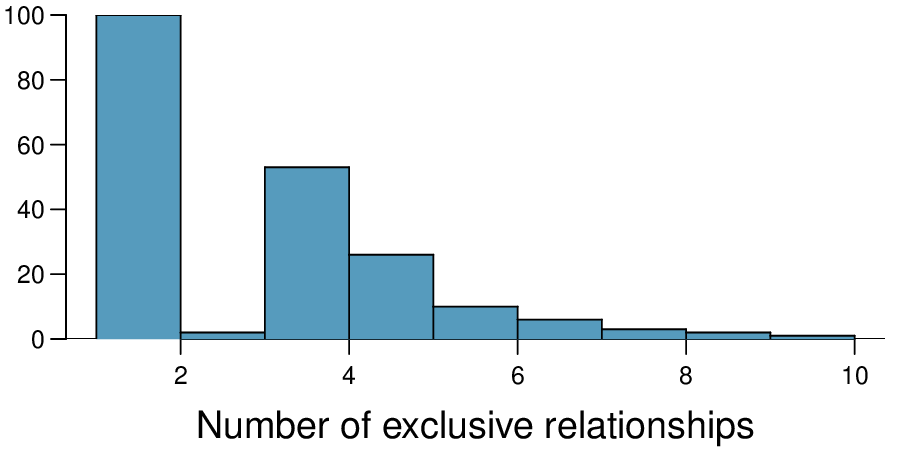
Estimate the average number of exclusive relationships Duke students have been in using a 90% confidence interval and interpret this interval in context. Check any conditions required for inference, and note any assumptions you must make as you proceed with your calculations and conclusions.
Independence: it is a random sample, so we can assume that the students in this sample are independent of each other with respect to number of exclusive relationships they have been in. Notice that there are no students who have had no exclu-sive relationships in the sample, which suggests some student responses are likely missing (perhaps only positive values were reported). The sample size is at least 30, and there are no particularly extreme outliers, so the normality condition is reasonable. 90% CI: \((2.97, 3.43)\text{.}\) We are 90% confident that undergraduate students have been in 2.97 to 3.43 exclusive relationships, on average.
8. Age at first marriage, Part I.
The National Survey of Family Growth conducted by the Centers for Disease Control gathers information on family life, marriage and divorce, pregnancy, infertility, use of contraception, and men's and women's health. One of the variables collected on this survey is the age at first marriage. The histogram below shows the distribution of ages at first marriage of 5,534 randomly sampled women between 2006 and 2010. The average age at first marriage among these women is 23.44 with a standard deviation of 4.72. 2
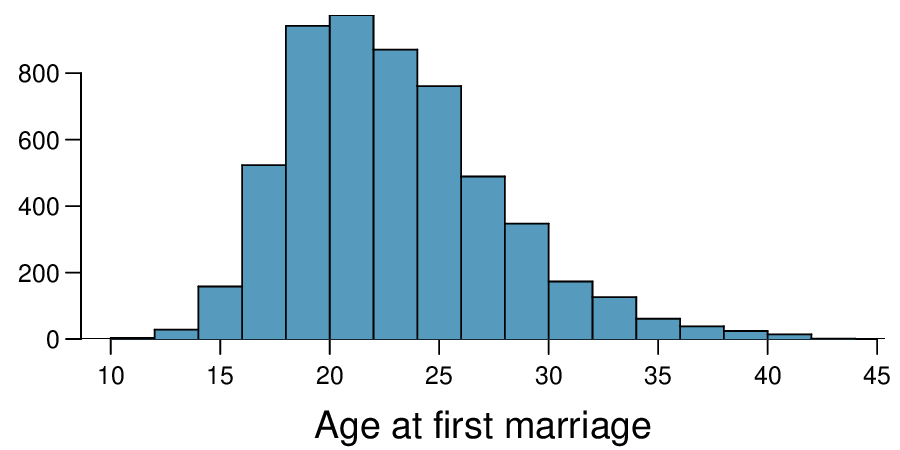
Estimate the average age at first marriage of women using a 95% confidence interval, and interpret this interval in context. Discuss any relevant assumptions.
9. Online communication.
A study suggests that the average college student spends 10 hours per week communicating with others online. You believe that this is an underestimate and decide to collect your own sample for a hypothesis test. You randomly sample 60 students from your dorm and find that on average they spent 13.5 hours a week communicating with others online. A friend of yours, who offers to help you with the hypothesis test, comes up with the following set of hypotheses. Indicate any errors you see.
The hypotheses should be about the population mean (\(\mu\)), not the sample mean. The null hypothesis should have an equal sign and the alternative hypothesis should be about the null hypothesized value, not the observed sample mean. Correction:
Because the change could go either way, we use a two-sided \(H_{A}\text{,}\)
10. Age at first marriage, Part II.
Exercise 7.4.1.8 presents the results of a 2006 - 2010 survey showing that the average age of women at first marriage is 23.44. Suppose a social scientist thinks this value has changed since the survey was taken. Below is how she set up her hypotheses. Indicate any errors you see.